A CDC Pipeline from Delta Tables to Synapse SQL
2022-04-08
Summary
I recently came upon a request asking how to build a CDC (Change Data Capture) process from Delta Tables to a Synapse Dedicated SQL Pool.
This post will detail the creation of this CDC pipeline.
To understand the pipeline, we must first understand what is being asked of this pipeline. The goal of this pipeline that we are going to create is to:
- Load in all available data from a delta table
- Bring in incremental changes using Change Data Capture data thereafter
This means we'll be building two Synapse pipelines to achieve this. First, the full load pipeline, and second, the incremental pipeline that will run on a schedule.
We will be using the following components to build out our pipeline:
First things first
The first thing we're going to do is create a table in our dedicated pool to track the loading and status of the tables we're pulling into Synapse SQL Pools.
We create this table in the dedicated SQL pool, and will use it in the full load and incremental pipelines.
CREATE TABLE [dbo].[CDCTableStatus]
(
-- this is the table name to process
[TableName] [varchar](256) NULL,
-- will is be processed by the pipeline
[Enabled] [bit] NULL,
-- what is the hash column we're using for distribution
[HashColumn] [varchar](512) NULL,
-- what is the unique column we're using for merging (this typically is the same as the hash column)
[UniqueColumn] [varchar](512) NULL,
-- the container name where the delta table is located
[ContainerName] [varchar](512) NULL,
-- the relative path of the delta table on the container
[Path] [varchar](2048) NULL,
-- The delta version of the last commit version of CDC data we've processed
[LastCommitVersion] [int] NULL,
-- The last time the table was updated.
[LastUpdatedAt] [datetime] NULL
)
WITH
(
DISTRIBUTION = REPLICATE,
CLUSTERED COLUMNSTORE INDEX
)
GO
Insert one record into the table to test:

Now that we have our control table, we can move on to building our full load pipeline.
The View
Our full load table will require us to pull data from the delta table directly, for the initial load of data. Recently, Synapse Serverless SQL added support for opening and reading Delta formatted datalake files. We are going to use this as our source for copying data into the SQL Pool. You may be asking yourself, "why aren't we using the a delta lake linked service as the source of our data?". The answer is quite simple. Using a serverless view allows us to specify schema specifics, such as column length, in the serverless view. When our pipeline reads this schema, it will use it to build out its SQL Dedicated Pool tables dynamically. Having the correct column lengths and other schema properties defined will greatly increase our performance in the dedicated pool.
In this post, we will focus on one specific delta table. The table contains country's populations by year. ie:
Canada, CAN, 2019, 3740000
Canada, CAN, 2020, 3760000
We will create a SQL serverless view that points directly to the delta table on the data lake.
--if you need to create a data source, this is shown below:
CREATE EXTERNAL DATA SOURCE GMDataLakeDevelopment
WITH ( LOCATION = 'https://datalakeaccountname.dfs.core.windows.net/container')
CREATE OR ALTER VIEW data.Populations
AS
SELECT * FROM OPENROWSET(
BULK 'curated/populations.delta/',
DATA_SOURCE = 'GMDataLakeDevelopment',
format = 'delta'
) with (
Id Int,
CountryName varchar(1500),
CountryCode varchar(3),
Year VARCHAR(4),
Value BIGINT
) as [Result];
This post makes the assumption that you understand delta tables and delta table CDC. We will be leveraging both of these during our pipeline build.
Now that the serverless view is created, we can move onto the pipeline itself.
Full Load Pipeline
The full load pipeline JSON can be found here
Pipeline Description
The full load pipeline has this general logic:
- Get the current version of the delta table, as well as other information from the control table
- Pull metadata information from the source serverless view including columns, types, lengths, etc and create a SQL create script.
- Get the latest delta table version using databricks
- Drop the SQL dedicated pool table (if exists), create the table using a hash distribution and then copy the data from the serverless view to the dedicated pool.
- Update the control table with the version of the delta table
Build the Pipeline!
First thing we do is what you expect: New Pipeline!
Parameters
This pipeline will load a single table. So we need some parameters. Create the following parameters:
- SourceDBOSchema - The serverless schema name
- SourceDBOTable - The serverless table name
- DestinationDBOSchema - The dedicated schema name
- DestinationDBOTable - The dedicated table name

Name it CDC Full Load.
Activity 1
Create a new lookup activity. We'll call it Get Control Table Information
Our source dataset for the lookup will be our dedicated sql pool. If you don't have a dataset for generic queries, let's create one!
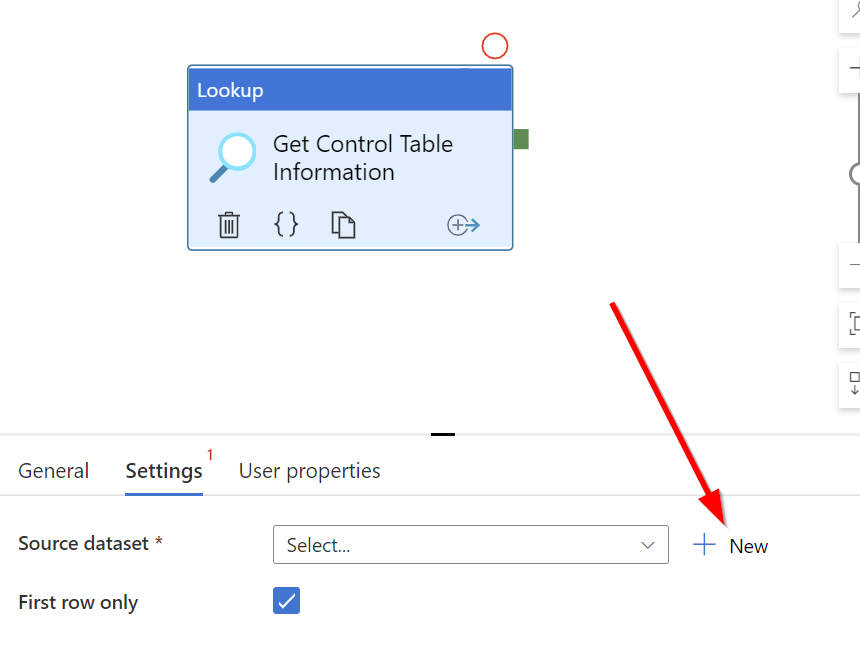
This post assumes all linked services have been created.
Type sql pool in the search box and select the Azure Synapse Dedicated SQL pool dataset:

Name the dataset, select your SQL pool and then click OK.

We now have a dataset we can use in our pipeline to query the data table.
We will be reusing this dataset elsewhere in the pipeline.
Now that we're back at the Lookup activity, we can specify the details. The query that we will be using is this:
SELECT * FROM dbo.CDCTableStatus
WHERE Enabled = 1
AND TableName = '@{pipeline().parameters.DestinationDBOTable}'

Activity 2 - Getting the table metadata
We're going to create another Lookup activity called Get Table Metadata. This activity will be responsible for retrieving the resulting SQL Pool table schema and SQL Create script.
We'll be using the SQLPoolQuery dataset again:

Set the query to this SQL script. Make sure to add this dynamic content.
Activity 3 - The databricks!
In this activity, we need to find out "what is the latest version of the delta table". This information will be used to mark our control table after the full copy has completed.
Here is the notebook we will be running. Import this notebook into your databricks cluster.
Once imported, set the values of the service principal and storage keys in the Set Storage And SQL Pool Authentication section. After that's done, we can then move onto activity #3.
This notebook will be used for the incremental load as well.
Add a Databricks Notebook activity to the pipeline.

Select your databricks linked service.

Set the settings as follows:

| Item | Setting | Description |
|---|---|---|
| DeltaTablePath | @activity('Get Control Table Information').output.firstRow.Path |
This is the relative path of the delta table, pulled from the control table |
| DeltaCommitVersion | 0 | not needed for the full load |
| ADLSAccountName | youraccountname | The name of your account |
| ADLSContainerName | @activity('Get Control Table Information').output.firstRow.ContainerName |
This is the container where the delta table is stored, pulled from the control table |
| SQLServer | null | not needed for full load |
| SQLDatabase | null | not needed for full load |
| SQLCDCTableName | null | not needed for full load |
| SQLCDCSchemaName | null | not needed for full load |
| WriteCDCData | false | specifies to the notebook to not try to output CDC data. This is false for the full load pipeline. |
Activity 4: The copy
Now we can finally move onto the copy activity.
The copy activity will actually pull data from the serverless view onto the SQL dedicated pool. We will call this activity Copy Data From Delta.

Our source will use a SQL Serverless Query this time. Let's go ahead and create it.


Once created, we can use it in our copy activity,

Go back to the connection tab of the data set and specify the table schema and name:
@dataset().Schema and @dataset().Table should be used as dynamic content of the table schema/name.

The query we will use will be:
Select @{activity('Get Table Metadata').output.firstRow.COLUMN_NAME}
FROM @{pipeline().parameters.SourceDBOSchema}.@{activity('Get Table Metadata').output.firstRow.TABLE_NAME}
Okay, now onto the sink settings. We will be using this time a dataset that specifies the schema and table in the SQL dedicated pool.

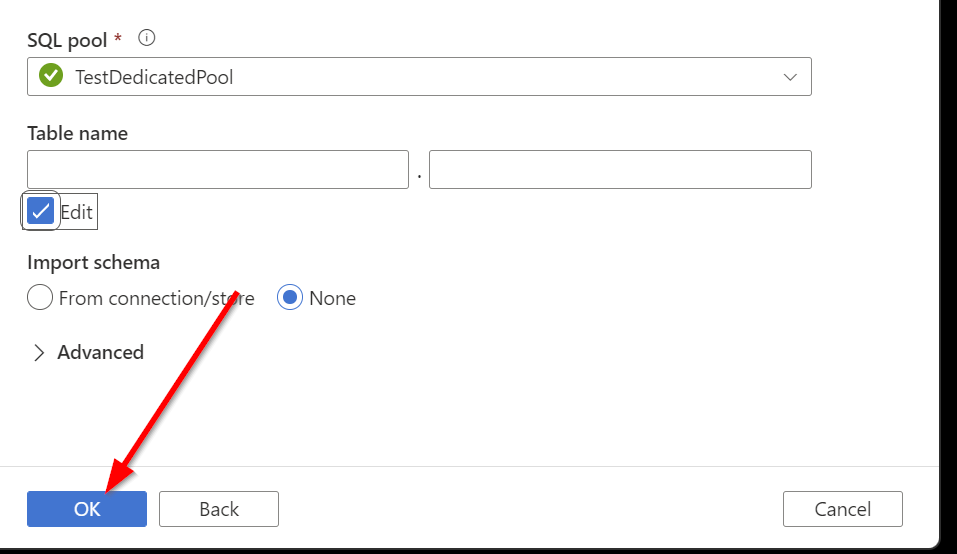
Open the dataset, and create the following parameters:

go back to the connection tab and enter the following dynamic fields:
Go back to the pipeline and your sink settings page should look like this:

Enter in the following for the dataset properties:
- Schema:
@pipeline().parameters.DestinationDBOSchema - Table:
@pipeline().parameters.DestinationDBOTable
In the precopy script, enter the following dynamic content:
IF OBJECT_ID(N'[@{pipeline().parameters.DestinationDBOSchema}].[@{pipeline().parameters.DestinationDBOTable}]','U') IS NOT NULL
BEGIN
DROP TABLE [@{pipeline().parameters.DestinationDBOSchema}].[@{pipeline().parameters.DestinationDBOTable}]
END
@{activity('Get Table Metadata').output.firstRow.SQL_CREATE}
Lastly, under settings, enable staging.
Activity 5 - The last one!
We'll create one final lookup activity, called Reset Table Status. This activity will set the latest commit version in the control table for the incremental to start from.

Create a new lookup activity and set the dataset as the SQLPoolQuery.
The Lookup query will be:
DECLARE @Date DATETIME;
SET @Date = GETDATE();
UPDATE @{pipeline().parameters.DestinationDBOSchema}.CDCTableStatus
SET LastCommitVersion = @{activity('Get Latest Version').output.runOutput}, LastUpdatedAt = @Date
WHERE TableName = '@{pipeline().parameters.DestinationDBOTable}';
SELECT GetDate() as RunDate;
Phew that was a lot!! But we're done our first pipeline! Let's remember what this pipeline does: The full load pipeline is responsible for loading the initial data from the delta table into our Synapse SQL Pool. It also marks the last version of the delta table into our control table for the incremental table to pick up.
Here is what your pipeline should look like:

The Incremental Pipeline
The incremental pipeline JSON can be found here
Description
Let's remember what the incremental load pipeline is supposed to accomplish: The main goal of this pipeline is to efficiently import any changes into the SQL Pool by leveraging the delta lake CDC data.
At a high level, the pipeline will do the following:
- Get the last commit version from the control table. This is the last version of data we imported, either by a full load or by a previous incremental load.
- Extract the delta table CDC data. This is done via a databricks notebook.
- Save the CDC data extracted into the SQL pool under a different schema. This is done via the previous databricks notebook specified.
- Merge the data using TSQL Merge into the sql pool table.
- Update the control table with the last commit version we processed
The Build
Create a new pipeline and call it CDCIncremental. Add the following parameters on the pipeline:

| Name | Description |
|---|---|
| SourceCDCSchema | The schema of the staging table (cgf or cdc, etc) |
| SourceCDCTable | The name of the cdc staging table in the dedicated pool |
| DestinationDBOSchema | The destination dedicated pool schema that we are merging data into |
| DestinationDBOTable | The destination dedicated pool table that we are merging data into |
Once done, we can start creating our activities.
Activity 1 - Retrieve the last commit version
Create a new lookup activity that uses the SQLPoolQuery dataset we created earlier. This activity is responsible for retrieving the last known commit that the pipeline processed.

The sql query for this lookup is:
SELECT * FROM dbo.CDCTableStatus WHERE Enabled = 1 AND TableName = '@{pipeline().parameters.DestinationDBOTable}' AND LastCommitVersion is not null
Activity 2 - Generate the CDC data
Using the previous databricks notebook we imported, we will be able to generate the CDC data. This notebook reads data from the delta table and exports it directly to a synapse sql pool table.

| Item | Setting | Description |
|---|---|---|
| DeltaTablePath | @activity('Get last Commit Version').output.firstRow.Path |
This is the relative path of the delta table, pulled from the control table |
| DeltaCommitVersion | @string(activity('Get last Commit Version').output.firstRow.LastCommitVersion) |
used to retrieve the CDC data that occurred since the last incremental run |
| ADLSAccountName | youraccountname | The name of your account |
| ADLSContainerName | @activity('Get last Commit Version').output.firstRow.ContainerName |
This is the container where the delta table is stored, pulled from the control table |
| SQLServer | nameofsqlpool.sql.azuresynapse.net | The name of the dedicated sql pool |
| SQLDatabase | testdb | The name of the database |
| SQLCDCTableName | @{pipeline().parameters.SourceCDCTable} |
The name of the staging dedicated pool table name we're going to copy into |
| SQLCDCSchemaName | @{pipeline().parameters.SourceCDCSchema} |
The name of the staging dedicated pool schema we're going to copy into |
| WriteCDCData | true | specifies to the notebook to output CDC data. This is always true for incremental loads. |
Activity 3 - TSQL Merge
Create a new Script activity.

Set the linked service as the built in SQL pool, or whichever SQL pool youre saving the data to.

Set the query to the following:
DECLARE @TargetTableName nvarchar(512) = '@{pipeline().parameters.DestinationDBOTable}'
DECLARE @TargetSchema nvarchar(512) = '@{pipeline().parameters.DestinationDBOSchema}'
DECLARE @CDCTableName nvarchar(512) = '@{pipeline().parameters.DestinationDBOTable}'
DECLARE @CDCSchema nvarchar(512) = '@{pipeline().parameters.SourceCDCSchema}'
declare @UpdateColumns VARCHAR(MAX);
declare @Columns VARCHAR(MAX);
Select @UpdateColumns = string_agg(CAST('T.' + x.COLUMN_NAME + ' = S.' + x.COLUMN_NAME AS VARCHAR(MAX)),', '),
@Columns = string_agg(CAST(x.COLUMN_NAME as VARCHAR(MAX)), ', ')
from INFORMATION_SCHEMA.COLUMNS x
WHERE TABLE_NAME = @TargetTableName
and TABLE_SCHEMA = @TargetSchema
select @UpdateColumns, @Columns
Declare @MergeStatement nvarchar(max);
set @MergeStatement
= ' MERGE ' +@TargetSchema +'.' + @TargetTableName + ' T USING '+ @CDCSchema +'.'+ @CDCTableName + ' S' +
' ON T.@{activity('Get last Commit Version').output.firstRow.UniqueColumn} = S.@{activity('Get last Commit Version').output.firstRow.UniqueColumn}' +
' WHEN MATCHED and S._change_type = ''update_postimage''' +
' THEN UPDATE SET ' +
@UpdateColumns +
' WHEN NOT MATCHED BY TARGET THEN INSERT (' +
@Columns +
') Values (' +
@Columns +
')' +
' WHEN MATCHED and S._change_type like ''%delete%''' +
' THEN DELETE;';
--' THEN UPDATE SET T.DeletedDateTime = GETDATE();';
Execute sp_executesql @MergeStatement;
This script executes the merge from the staging table to the destination table.
Activity 4 - Update the control table
Add a new lookup activity with the SQLPoolQuery dataset. This activity will update the control table with the last commit version that we processed.

Set the query to:
UPDATE CDCTableStatus
SET LastCommitVersion = @{int(activity('GenerateCDCData').output.runOutput)}
WHERE TableName = '@{pipeline().parameters.DestinationDBOTable}';
SELECT 0 as ReturnSTatus;
Pipeline Summary
We're done building the incremental pipeline! It should look like this:

Testing
Now let's test!
The first thing we'll do is run the full load pipeline.
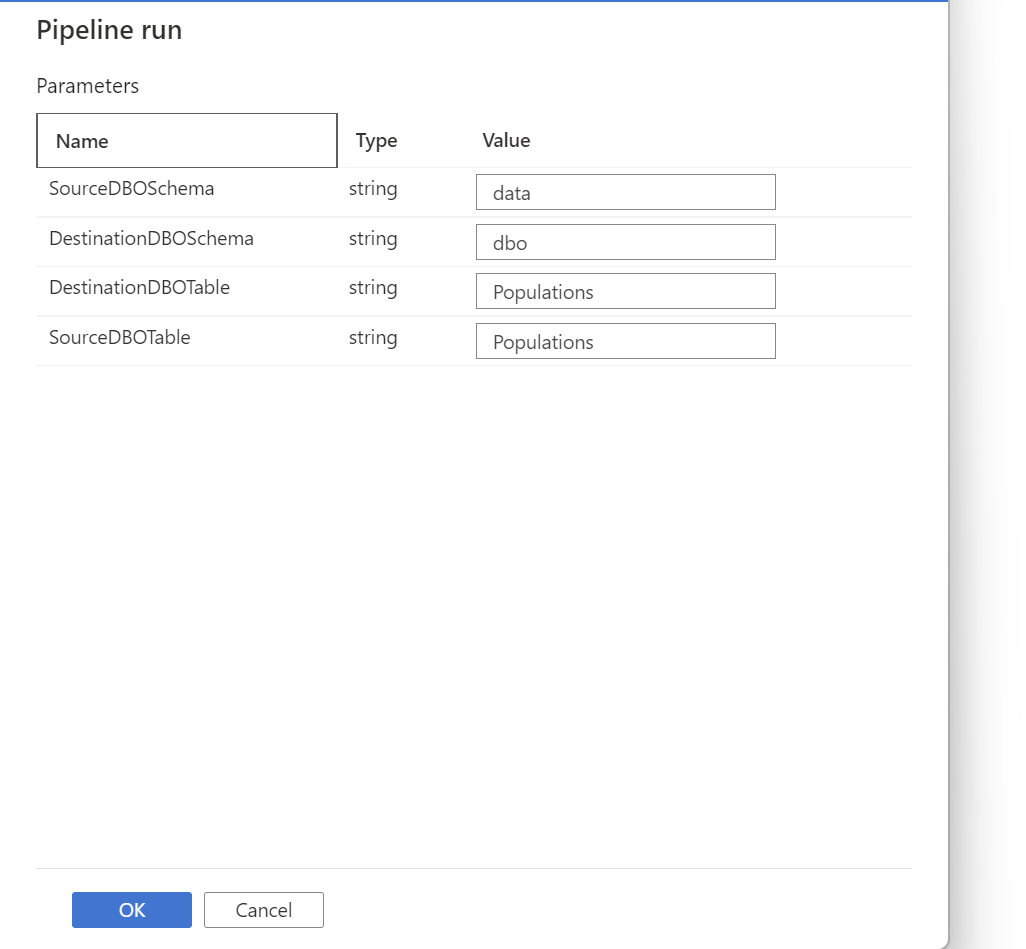

After this runs, we should see the SQL pool table be FULLY populated with data.
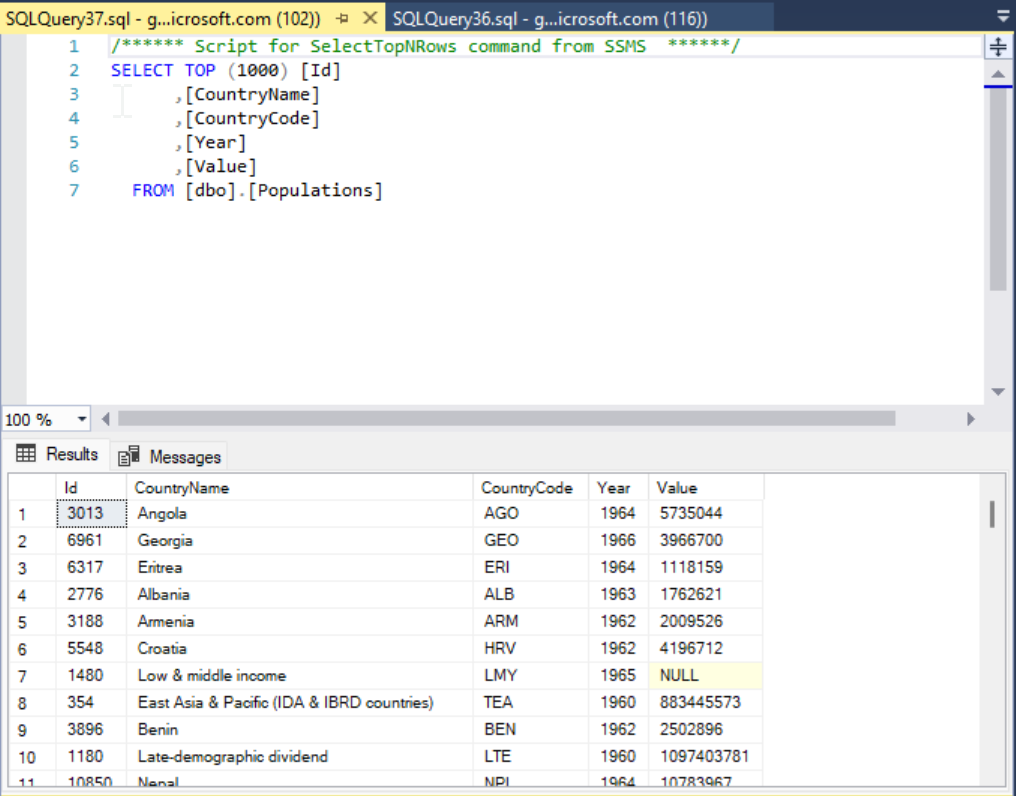 SUCCESS!
SUCCESS!
The next thing we need to do is modify the delta table data. We will leave this as an exercise to the reader.
Once you're updated some data in the delta table, we're ready to test the incremental.
Run the incremental pipeline:
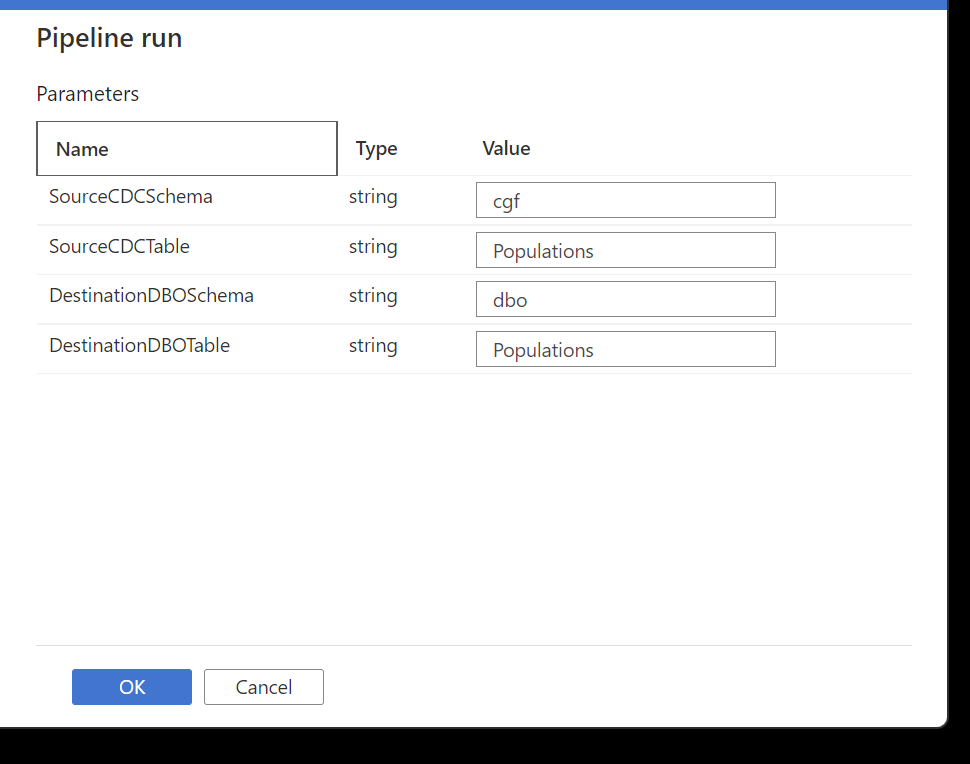
After the databricks notebook runs, we should see the following in the staging table:

Change data in the database!! Superb!
Once the pipeline fully runs, you can check to make sure the changes were propagated to your dedicated SQL table.
Summary
We created two pipelines, full load, and incremental. These pipelines replace date in delta lake data efficiently and quickly using the CDC feature of delta lake and capabilities of Synapse SQL Pools. The pipelines detailed in this post only show how to replicate data for one specific table. In a later post, we'll be showing how to use a lookup to iterate through a control table to execute existing pipeline.